

2017 was cool. Medical AI progressed apace, the AI community grew up some and got a bit creative, and I made some predictions that mostly held up to vague scrutiny.
On the technical side, the research community decided to go all in on generative models, pivoting away from making diminishing gains at worn out supervised learning tasks. At the start of the year we had were deep in the uncanny valley for speech synthesis, image and video generation, super-resolution, automatic colourisation, and so on. By the end of the year these tasks have been at least partially solved.
Text-to-speech
Mid 2016
Late 2016
Late 2017
Image generation

Late 2016 image generation. Recognisable birds, but still quite low res and with some bizarre errors (too many eyes and legs, etc).
 Late 2017 image generation. Still a few minor artefacts, still not quite getting simple backgrounds right, but in general I can’t tell that these are not real people.
Late 2017 image generation. Still a few minor artefacts, still not quite getting simple backgrounds right, but in general I can’t tell that these are not real people.
This focus on generation has meant that we haven’t seen major breakthroughs in models that are immediately useful in medical contexts. There will probably be a role for GAN-produced data augmentation, and these systems are likely to be better at learning the edges of a data manifold than purely supervised learners, but so far I haven’t seen any clinically convincing medical uses.
Super-resolution has been used to tidy up noisy medical images and allow for radiation dose reductions, but since it is doing inpainting by population statistics I’m pretty doubtful that it will be reliable enough for use with diagnostics.

The upscaled image from this paper in 2016 is sharp and has realistic fabric textures, but the patterns are completely different from the original. This property of these models limits how useful they will be in medicine, because there is no guarantee that the generated data will match reality.
More relevant to medicine, we have seen the conversation amongst researchers focus on issues of interpretability (important but overblown in my opinion, expect an upcoming blog post on this topic*), and more recently about rigour in experimental design and analysis. Both of these topics are currently pain points in medical applications, and the latter will need a fair bit of work to bridge the culture gap between the medicine and machine learning communities.
Looking away from research towards applications, 2017 has been the year that AI starts changing work, albeit just slowly enough that most people haven’t really noticed yet. There has been an explosion in AI systems at the business and consumer level, most notably with smart speakers and voice assistants, but also in more traditional domains like farming.
And of course, the 7th of November in 2017 was the moment that level 4 autonomous driving became a functional reality, even if no-one seemed to notice. This is a huge watershed, and the starting point of the first massive industry-wide disruption caused by AI.
In 2017 our community also started to look inward and get our ships in order. Not only has algorithmic bias gained visibility, for better and worse, but so have our own much more human failings.
I don’t comment on culture very much here, mostly because as an Australian I am quite geographically isolated from the bulk of the machine learning community, but some issues do need to be discussed openly. In the last month we have seen a spotlight cast on the sexual harassment that occurs within our discipline. The response so far has been fairly robust, although we will have to wait and see if the relevant organisations follow through. Will they do the hard work needed for cultural change, or will they quietly decide that lip service is easy and fixing things is too hard?
While this is certainly not isolated to the machine learning community (medicine is at least as bad), it really reinforces the need for all of us to do more than “just be decent”. The discussion so far has focused on several bad actors, but I hope all of us are reflecting on the fact that these researchers’ behaviour was tolerated at all levels of the community for a very long time. As one of Australia’s top military leaders once said, “the standard you walk past is the standard you accept.”
Don’t let the source put you off, this is one of the most powerful institutional messages about harassment and inclusivity I have seen. Watch, listen, put into practice.
We can do much better, and I hope we as a community become more proactive at fighting all forms of harassment and bigotry in our profession.
So, that was 2017. With that quick overview out of the way, let’s see how I did predicting the year that was.
My scorecard
Around this time last year I made a series of predictions about how 2017 would go for medical AI. It is time to see how those predictions stacked up to reality.
If you haven’t read that post, I divided progress into what I called the “3 phases of medical AI trials“. For the record, I’m not convinced that this classification is an ideal way to look at medical AI research**, but it still holds up fairly well.
Phase 1 research is the proof of concept work. Typically small datasets, usually with promising results of ill-defined relevance to clinical practice. In the world of pharmaceuticals, successful phase 1 trials have a 10% chance of translating into a product, at an average of 8 years to reach market.
Phase II research is getting into the serious work. Large datasets, comparing models to some reasonable baseline, and presenting results that are believable in a broader context, these studies are time-consuming and difficult to perform. We had a single phase II trial in 2016, the Google paper on retinopathy assessment which I mention every second blog post 🙂
Phase III trials are the real deal. The AI system is applied as a tool in practice, in a large randomised controlled trial. This deals with the major question that phase II trials leave unanswered: how do we actually use human-level or better AI systems in practice? It isn’t actually clear how to incorporate even superhuman AI systems into clinical workflows safely and effectively. Again, another blog post for the future.
Phase I
I predicted that we would see the quantity of medical AI research (defined as deep learning for medical data) at least double during 2017. This appears to have come to pass. Like last year, I looked through a number of Google Scholar searches to estimate this across a period of six months. These are pretty rubbery figures (conference months are huge outliers, and Scholar isn’t really a definitive source), but it is at least consistent as a method.
2016: 5-10 per month (closer to 5)
2017: 10-20 per month (probably around 15)
The other major change in the literature was the massive explosion in the number of editorials, overview articles, and position statements on deep learning. Quite honestly, there are almost as many of these per month as there are actual research papers! I did kind of mention this in my “miscellaneous predictions” for 2017 (@ number 3), but the scale of it has surprised me.
We could be cynical and say that there are more people talking about deep learning than actually doing deep learning, but I prefer to view this in a positive light. 2017 is the year that doctors started to take this technology seriously. Specialist group meetings, journals large and small, newsletters, grand rounds, working groups, and governance bodies are all discussing artificial intelligence. There are still a lot of naysayers, but it feels like the discussion turned a corner in the last twelve months and AI has become part of the mainstream medical zeitgeist.
SCORE
I got this one spot on, but probably underestimated the vast proliferation of non-research discussion about AI.
Phase II
I predicted that we would see 3-5 phase II trials in medical AI in 2017, mostly from established industry groups.
The year started with a bang, with Nature publishing Stanford’s dermatology paper in January.
But then there was a long drought, and no large convincing trials came out for most of the year.
But as the year drew to a close everyone seemed to publish at once. Most of these studies have some weaknesses, or unimpressive results, or exaggerated claims, but they probably all qualify as Phase II research. This is actually a problem with my prediction; I didn’t clearly define what Phase II, and there are several possible interpretations. I will discuss some ways to better assess the quality of Phase II research in the new year, but all I am really asking here is “is there a large dataset, with believable results***?”
The most convincing study came from a large competition to identify lymph node metastases in breast cancer cases from pathology slides. I’ve talked about this task before, which is cool and important. This paper draws together the results from multiple participants, and compares them against a well performed human baseline. I’ll talk about this study some more in the future, but it is fair to say that this work is up there with the Google retinopathy paper.
The next two highest quality studies I saw were Cardiologist Level Arrhythmia Detection Using Neural Networks and MURA Dataset: Towards Radiologist-Level Abnormality Detection in Musculoskeletal Radiographs, interestingly both from the Stanford ML Group. I would say these are “moderate quality” Phase II research, where we can believably extrapolate the results to some extent, but the direct clinical implications are somewhat unclear.
The rest of them, including detecting brain bleeds, pneumonia, hip fractures (from my team, by the way), a variety of brain pathologies, and a competition on bone age assessment, all sneak into the Phase II classification by virtue of large-ish training sets and results that pass the sniff test, at least if you look past some of the claims. The direct relationship between these pieces of research and clinical practice is fairly uncertain.
SCORE
I said we would see 3 to 5 studies in this category, but it turns out that this was a bit non-specific. We had 3 moderate quality or better Phase II trials, and another half dozen studies that probably count as Phase II, but have some limitations.
If we hold the Google retinopathy paper as the yardstick, then there was really only 1 paper this year that got there. If we have a more permissive definition for phase II, there could have been as many as 8. I’m going to give myself a solid B+ for this prediction :p, but with a proviso that any future predictions for this category will need to be more specific.
I also predicted that most of this work would come from established industry groups rather than universities or start-ups, and here I was completely wrong. It was actually a mix of the latter two groups, with no further corporate breakthroughs.
Phase III
In 2016 we had no phase III trials.
In 2017 I predicted we would have no phase III trials.
In 2017 we had no phase III trials.
SCORE
This one was a gimme. I got it right, but it was pretty obvious. Clinical trials are hard, expensive, and time consuming.
Miscellaneous
I also made some miscellaneous predictions for 2017, some of which were falsifiable.
- AR/VR and 3d printing won’t achieve much: yep, still true. These are really cool technologies, with no obvious medical use cases in my opinion. I haven’t seen much that wasn’t a gimmick. Maaaybe 3d printed bone scaffolds and organ transplants will be a big deal, but these seem to be a long way from clinical usage.
- Sub-$1000 genome: depends who you talk to. There are bargain basement offers for as low as $450
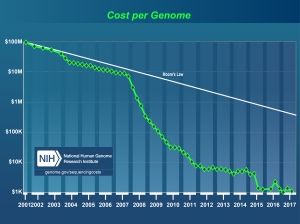
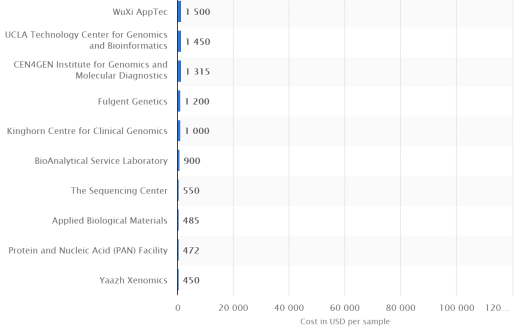 but if we take the published graphs from genome.gov as fact (which is really what this claim was based on), then I actually got this one wrong. The price is still sitting around $1000.
but if we take the published graphs from genome.gov as fact (which is really what this claim was based on), then I actually got this one wrong. The price is still sitting around $1000.
- Biotech will go gangbusters: not a really falsifiable prediction here, but I’d say this was correct in spirit. Gene therapies have been getting approved by the FDA, and in the tail end of the year we have seen the decades long maturation of this technology hit a real tipping point. Serious journals are publishing results about near-term, single dose cures for many genetic conditions including adrenoleukodystrophy, haemophilia A, and spinal muscular atrophy. This is probably the most exciting news in medicine, much more so than AI. Safe, effective gene therapy is going to be a game-changer in so many ways, and not just for rare genetic conditions.
- Medical apps: so the big news this year is that most medical apps, as long as they don’t give actual medical advice or analyse medical data, no longer need to be reviewed by the FDA. Diet trackers, exercise monitors, medication reminders and so on can all be marketed direct to the public without any regulatory approval. This will have big implications in 2018 onwards, but I really don’t know enough about health apps to judge my prediction here. General information apps like Epocrates and MDCalc have high download numbers, Fitbit and similar are obviously popular, but it doesn’t excite me. I just don’t see it changing health significantly. Maybe targeted apps/services like Livongo and Omada Health might be more interesting. I’m not confident about my knowledge of this space at all though. If anyone knows lots about this stuff, drop me a line.
SCORE
Not sure how to score this. Maybe another B+?
OVERALL SCORE
Couple of A’s, couple of B’s? Pretty good, I reckon.
So there we go. A brief look at the world of medical (and other) AI in 2017. I think my predictions stacked up pretty well, but since the technology is so new the change is slow and therefore more predictable. Next year will be more explosive, and will probably be a harder test.
As a quick aside, I think this sort of yearly summary and prediction is both fun and worth doing if you have some spare time. I feel like I understand my field more after I do it. It also sharpens my focus on what might be useful and not so useful to research in the coming year.
The eponymous Miles Brundage does predictions as well, mostly around RL and NLP, and I am eagerly awaiting the 2017 follow up on his rigorous predictions.
I’m a total stats scrub. He does Brier scores, I do vague grades based on “the vibe” 🙂
Anyway, thanks for reading in 2017! I’m looking forward to the coming year, and making some new predictions soon.
* I currently have more than 10 new posts at various stages of completion. Lots of cool stuff to talk about!
** It has become more clear that for many applications, a good “phase II” trial may be enough to achieve regulatory approval. For systems that advise, measure, or predict, this could satisfy even with the so far fairly conservative FDA. That said, truly disruptive changes are still looking at translational phase III research.
*** Note that I say “believable results”, not “believable claims”. The authors’ interpretation of the results can be flawed, but the results as presented are believable.

Hi Luke,
I am new to your blog but totally agree with you on the necessary synergy between the medical and AI domains. It is particularly disappointing to me that some recent papers are published on clinical projects that totally devoid of any clinicians on the project.
I am the organizing chair of an annual meeting called Artificial Intelligence in Medicine (AIMed)(AIMed-MI3.com) that just concluded earlier this month (12/11-14). We had over 500 attendees with about 40% clinicians and we should discuss your participation as a physician-data scientist in the near future. I am also forming a group called ai.MD or AI+MD (tentative names) that will try to gather all MDs with a data science passion and/or education like yourself. This group can serve as a coalition of physicians with adequate data science background that can help guide AI in medicine (I call it “medical” intelligence). Finally, I have just released an eBook on this topic and will be finishing a book project next year and we would really like to have you write a commentary on a topic of your choice.
I am so glad I found your blog and will keep in touch!
Keep up the good work!
Best,
Anthony (AChang007@aol.com)
(Anthony C. Chang, MD, MBA, MPH, MS)
LikeLike
Thanks Anthony, I’ll email you.
LikeLike
Great post, thanks for your thoughts. The text-to-speech is really interesting, by next year they could have a robot instead of a person on ACX and people would be none the wiser.
I think we will see next year loads of improvements to existing apps, here are a few I want to share if they are not on your radar.
One I’ve been tracking for while is Recovery Record (Eating Disorder Management), especially as they can reach people that are unable to have any other form of treatments and they are evidence oriented: https://dx.doi.org/10.1002/eat.22386
It also good to see the detection of sleep apnea being developed further, sleep is a really important thing for people to nail.
http://apnea.cs.washington.edu/
I’m personally interested that air pollution is being a hot topic for policymakers who want a smart city.
Google again have helped by showing that the street view cars are able to map urban areas air with a range, quality and accuracy nobody has managed before.
http://apte.caee.utexas.edu/google-air-mapping/
LikeLike
Thanks Pieter, those links are useful.
LikeLike
Nice overview of the past year. I’d like to translate it to Chinese to make it more approachable for Chinese AI developers. Can you give me the permission to translate and publish it on a WeChat (a popular social application in China) account named 论智 (basically means “on intelligence” in Chinese) and a corresponding website? Thanks.
LikeLike
Sure, feel free. Lining back here would be appreciated. I think it is already translated into Chinese at https://yq.aliyun.com/articles/326174
LikeLike
I were not aware of that this overview has already be translated into Chinese. Thanks for your supportive attitude anyway. Looking forward to translate your new blog posts. 🙂
LikeLike