

I’ve been talking in recent posts about how our typical methods of testing AI systems are inadequate and potentially unsafe. In particular, I’ve complained that all of the headline-grabbing papers so far only do controlled experiments, so we don’t how the AI systems will perform on real patients.
Today I am going to highlight a piece of work that has not received much attention, but actually went “all the way” and tested an AI system in clinical practice, assessing clinical outcomes. They did an actual clinical trial!
Big news … so why haven’t you heard about it?
The Great Wall of the West

Matt Damon in a monster/wuxia film. Also mostly ignored by the public, but for different reasons 🙂
Tragically, this paper has been mostly ignored. 89 tweets*, which when you compare it to many other papers with hundreds or thousands of tweets and news articles is pretty sad. There is an obvious reason why though; the article I will be talking about today comes from China (there are a few US co-authors too, not sure what the relative contributions were, but the study was performed in China).
China is interesting. They appear to be rapidly becoming the world leader in applied AI, including in medicine, but we rarely hear anything about what is happening there in the media. When I go to conferences and talk to people working in China, they always tell me about numerous companies applying mature AI products to patients, but in the media we mostly see headline grabbing news stories about Western research projects that are still years away from clinical practice.
This shouldn’t be unexpected. Western journalists have very little access to China**, and Chinese medical AI companies have no need to solicit Western media coverage. They already have access to a large market, expertise, data, funding, and strong support both from medical governance and from the government more broadly. They don’t need us. But for us in the West, this means that our view of medical AI is narrow, like a frog looking at the sky from the bottom of a well^.
What would be really cool is if anyone who knows details about medical AI in China wanted to get in touch and let me know what is actually happening over there. I’d love to do a blog post highlighting leading companies and projects that actually have products working with real patients in real clinics. The same goes for AI teams in Africa, India, Southeast Asia and anywhere else that doesn’t get news coverage or exposure.
The first clinical trial in medical AI
“Real-time automatic detection system increases colonoscopic polyp and adenoma detection rates: a prospective randomised controlled study” by Wang et al. describes a study performed at the Sichuan Provincial People’s Hospital in Chengdu, China.
It bills itself as a prospective randomised control trial. Others have claimed to do AI clinical trials before, but have all (to the best of my knowledge) fallen short.
This one lives up to the billing.
An AI team/company/startup called Shanghai Wision AI Co. produced a system that detects polyps (little tumours) in the bowel wall during a colonscopy. They did performance testing previously which showed a per image AUC of 0.984 in a retrospective experiment, and a variety of other promising results. But the defining characteristic of a clinical trial (in my opinion) is; “how does it change patient outcomes in practice?” In this case, does using the AI system translate into diagnosing more cancer, and does it lead to more unnecessary biopsies?
In the paper, they use the system in actual clinical practice. The endoscopist did their normal colonoscopy, but the AI was watching them work in real time. If it saw a polyp it would beep, and the endoscopist could then turn to look at a different screen which shows a floating rectangle overlying the video to highlight the polyp.
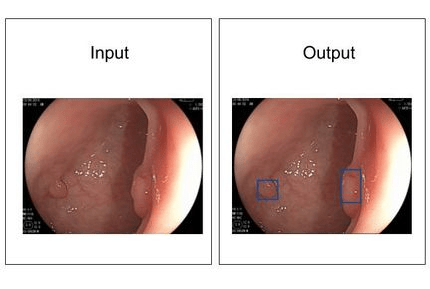
The two screens the endoscopist has available. They only look at the right image (the AI augmented view) if the AI alerts them it has seen something important.
They measure how often the endoscopist agrees with the AI system, but if they left it there it would just be another example of performance testing gussied up with the veneer of prospective cohort selection (which some audacious researchers have claimed makes it a clinical trial by itself).
But this team took the step that actually elevates the work from an experiment into a clinical trial: they removed the polyps!
These are polyps that the AI noticed, which the endoscopist had not seen (although the endoscopist could still overrule the system, which would be recorded as a false alarm). In this study, they performed invasive medical procedures on patients because of the output of an AI system.
Before you get all “of course they did, it was China, something something safety standards”**, I want to be clear – they did exactly what needs to be done to show that a system is safe. After you do your performance testing and get promising results, you need to actually test what happens in practice. This is right. This is good.
A colonoscopy AI in a clinic doesn’t just make a visual decision. It (with the endoscopist) decides who needs a biopsy. If your testing doesn’t include actually doing the biopsies, then medical AI safety, you’re doing it wrong.
So, what did they find?
Unsurprisingly, they did a lot more biopsies. They removed almost double as many polyps in the AI group (500 vs 270 in the “normal colonoscopy” group, in roughly the same number of procedures). This number in itself isn’t that interesting, the exciting part is that they specifically found a lot more adenomas when the removed lesions were examined under a microscope (adenomas are the polyps at risk of turning into cancer). They found 1.89 times more polyps overall, but also found 1.72 times more adenomas. This seems like a huge increase in the number of potential cancers.
But the fact they find adenomas doesn’t mean the patients will be better off. The team recognised this, and also analysed what type of adenomas they found.
As you would expect, the AI mostly found small “diminutive” adenomas. Humans are unlikely to miss the big, dangly ones (dangly is the technical term, but some people call these lesions “pedunculated”). The AI couldn’t add much in this group of lesions, detection rates are already nearly 100%.
We also know the smaller lesions that the AI system founds have a lower risk of cancer than big ones (more cells = more risk), but the team acknowledges this. They say “further studies should address the role of CADe on decreasing interval cancer, which is the main goal of any screening colonoscopy.” This, again, is sensible.
But it will take years to run those experiments, so the question to ask right now is “when is it safe enough to use?”
Medical AI safety: doing it right
While we don’t have data on the primary endpoints of interest (interval cancer rate, cancer mortality), we do have safety data. They recorded both the false alarm rate (when the endoscopist over-ruled the AI system and said “I’m not biopsy-ing that”) and the complication rate (the risk of biopsy is that you might puncture the bowel).
Amazingly, the false alarm rate was tiny. Despite a per image false alarm rate of around 5% reported previously, they somehow end up with one false alarm per 13 colonoscopies in practice! I don’t know exactly how they achieved this (presumably they chose a pro-specificity threshold and did some “only if it is on multiple frames” heuristic magic), but it sounds amazing.
The complication rate was also tiny, it was zero! With almost 500 biopsies in the 500-ish cases with CAD and no complications, we are fairly safe to assume the risk is unlikely to be much higher than normal.
One other major issue I have with most medical AI papers, which I haven’t written much about because I am actively researching the effect, is that you need to carefully investigate what cases the system gets wrong. Just because an AI system is as good as a human (gets as many or fewer cases wrong), it doesn’t mean they are the same cases. What if the human errors are benign and never lead to harm, but the AI errors are life-threatening^^? The only way to understand the error distribution is to actually look at the images (something I have said quite a bit).

You can probably see how useful this is for a clinician. If the system decides it sees a polyp, the user could immediately look for drug capsules and bubbles, the equivalent of a radiologist considering imaging artefacts as a cause of unusual visual findings. I feel this sort of error analysis is waaaaay more clinically useful than any interpretability technique (although in practice it is fairly common to have no appreciable reason for the errors).
So given this safety data, and additional analysis, what do I think?
If they had only doing performance testing, even if I had ten times the guts^ I wouldn’t be willing to use this AI system on patients. There are tons of ways the results in performance testing can be misleading.
But they did a clinical trial, with an appropriate surrogate endpoint. They even had a very even handed discussion of possible failings of the study design, and delightfully refer to the possibility of user bias due to the lack of blinding as the endoscopists showing too much “competitive spirit” when they are being watched, which has apparently been reported in previous research.
Regarding blinding, obviously it was impossible here. They have a machine that goes ping for the AI arm. Who would run a blinded AI experiment …
well, this team would!
They have recently posted an abstract for a double blind study with sham AI! That is a serious commitment to scientific exploration, and something that I am greatly looking forward to seeing more detail on if/when they publish a full report.
In summary, I do think they have done the work needed to show a reasonable level of safety and efficacy, enough to justify clinical use. We still need to see if it works with long term outcomes, and if it works in other populations (which they also acknowledge), but in the mean time their own sign-off sounds about right:

So there you go. An AI clinical trial that (in my view) provides enough evidence to justify clinical use.
Such a thing is as rare as a Phoenix feather^.

Interesting post & research! For following China related ai developments, I have found this blog helpful –
https://chinai.substack.com/
LikeLiked by 1 person
That blog looks really interesting. The geopolitics of AI is exciting, incredible, and concerning at the moment! I’ll definitely have a read, thanks for the heads up.
LikeLike
Great post on medical AI. Looking forward to more diagnostic AI tests in the future in the line of “prevention is better than cure”.
LikeLike