

Is this the darkest timeline? Are we the baddies?
Hi! It has been a while!
My blogging was extremely slow in 2020 and so far in 2021 for a few reasons, including having a new baby (with a lot of stay at home parenting 😴), starting a new job (I’m formally employed as a researcher at the Australian Institute for Machine Learning now) and embarking on supervising PhD students (🥳), as well as some other stuff that I will be talking about sometime soon.
But one thing that has taken up a lot of time recently has been a piece of work that I’m proud to have been a part of, and which has culminated in a preprint* titled Reading Race: AI Recognises Patient’s Racial Identity in Medical Images.
This paper was a huge undertaking, with a big team from all over the world. Big shout out to Dr Judy Gichoya for gathering everyone together and leading the group!
This work is also, in my opinion, a huge deal. This is research that should challenge the status quo, and hopefully change medical AI practice.
The paper is extensive, with dozens of experiments replicated at multiple sites around the world. It comes with a complete code repository so anyone can reproduce any part of it (although a minority of the datasets are not publicly available, and a few more require an approval process). It even comes with the public release of new racial identity labels for several public datasets, which were obtained with the collaboration of the dataset developers.
We want feedback and criticism, so I hope everyone will read the paper. I’m not going to cover it in detail here, instead I wanted to write something else which I think will complement the paper; an explanation of why I and many of my co-authors think this issue is important.
One thing we noticed when we were working on this research was that there was a clear divide in our team. The more clinical and safety/bias related researchers were shocked, confused, and frankly horrified by the results we were getting. Some of the computer scientists and the more junior researchers on the other hand were surprised by our reaction. They didn’t really understand why we were concerned.
So in a way, this blog post can be considered a primer, a companion piece for the paper which explains the why. Sure, AI can detect a patient’s racial identity, but why does it matter?
Disclaimer: I’m white. I’m glad I got to contribute, and I am happy to write about this topic, but that does not mean I am somehow an authority on the lived experiences of minoritized racial groups. These are my opinions after discussion with my much more knowledgeable colleagues, several of whom have reviewed the blog post itself.
A brief summary
In extremely brief form, here is what the paper showed:
- AI can trivially learn to identify the self-reported racial identity of patients to an absurdly high degree of accuracy
- AI does learn to do this when trained for clinical tasks
- These results generalise, with successful external validation and replication in multiple x-ray and CT datasets
- Despite many attempts, we couldn’t work out what it learns or how it does it. It didn’t seem to rely on obvious confounders, nor did it rely on a limited anatomical region or portion of the image spectrum.

So that is a basic summary. For all the gory details see the paper. Now for the important part: so what?
An argument in four steps
I’m going to try to lay out, as clearly as possible, that this AI behaviour is both surprising, and a very bad thing if we care about patient safety, equity, and generalisability.
The argument will have the following parts:
- Medical practice is biased in favour of the privileged classes in any society, and worldwide towards a specific type of white men.
- AI can trivially learn to recognise features in medical imaging studies that are strongly correlated with racial identity. This provides a powerful and direct mechanism for models to incorporate the biases in medical practice into their decisions.
- Humans cannot identify the racial identity of a patient from medical images. In medical imaging we don’t routinely have access to racial identity information, so human oversight of this problem is extremely limited at the clinical level.
- The features the AI makes use of appear to occur across the entire image spectrum and are not regionally localised, which will severely limit our ability to stop AI systems from doing this.
There are several other things I should point out before we get stuck in. First of all, a definition. We are talking about racial identity, not genetic ancestry or any other biological process that might come to mind when you hear the word “race”. Racial identity is a social, legal, and political construct that consists of our own perceptions of our race, and how other people see us. In the context of this work, we rely on self-reported race as our indicator of racial identity.
Before you jump in with questions about this approach and the definition, a quick reminder on what we are trying to research. Bias in medical practice is almost never about genetics or biology. No patient has genetic ancestry testing as part of their emergency department workup. We are interested in factors that may bias doctors in how they decide to investigate and treat patients, and in that setting the only information they get is visual (i.e., skin tone, facial features etc.) and sociocultural (clothing, accent and language use, and so on). What we care about is race as a social construct, even if some elements of that construct (such as skin tone) have a biological basis.
Secondly, whenever I am using the term bias in this piece, I am referring to the social definition, which is a subset of the strict technical definition; it is the biases that impact decisions made about humans on the basis of their race. These biases can in turn produce health disparities, which the NIH defines as “a health difference that adversely affects disadvantaged populations“.
Third, I want to take as given that racial bias in medical AI is bad. I feel like this shouldn’t need to be said, but the ability of AI to homogenise, institutionalise, and algorithm-wash health disparities across regions and populations is not a neutral thing.
AI can seriously make things much, much worse.

Part I – Medicine is biased
There has been a lot of discussion around structural racism in medicine recently, especially as the COVID pandemic has highlighted ongoing disparities in US healthcare. The existence of structural racism is no surprise to anyone who studies the topic, nor to anyone affected by it, but apparently it is still a surprise to some of the most powerful people in medicine.
Sometimes medical bias is because different patient groups will need different clinical approaches, but we don’t know that because the evidence that supports clinical practice is biased; most clinical trials populations are heavily skewed towards white men. In fact, in the 1990s the US Congress had to step in to demand that trials include women and racial/ethnic minorities**. In general, trials populations don’t include enough women, people of colour, people from outside the US or Europe, people who are poor, and so on***.

There is a long and storied history of the effects this has had. Examples include medicines for morning sickness that cause birth deformities but weren’t tested on pregnant women, imaging measurements that tend to overestimate the risk of Down’s syndrome in Asian foetuses, and genetic tests that fail for people of colour.
But medicine is biased at the clinical level too, where healthcare workers seem to make different decisions for patients from different groups when the correct choice would be to treat them the same. A famous example was reported in the New England Journal of Medicine, where blind testing of all pregnant women in Pinellas County FL for drug use revealed similar rates of use for Black and white women (~14%), but in the same period of time Black women were 10 times more likely to be reported to the authorities for substance abuse during pregnancy. The healthcare workers were, consciously or unconsciously, choosing who to test and report. This was true even for private obstetrics patients:
In the private obstetricians’ offices, black women made up less than 10 percent of the patient population but 55 percent of those reported for substance abuse during pregnancy.
Chasnoff et al, NEJM, 1990
There are innumerable other examples that can be described for any minoritised group. Women, people of colour, and Hispanic white men are less likely to receive adequate pain relief than non-Hispanic white men. Transgender patients commonly report being flat-out denied care, or receiving extremely substandard treatment. Black newborns are substantially more likely to survive if they are treated by a Black doctor.
In medical imaging we like to think of ourselves as above this problem, particularly with respect to race because we usually don’t know the identity of our patients. We report the scans without ever seeing the person, but that only protects us from direct bias. Biases still affect who gets referred for scans and who doesn’t, and they affect which scans are ordered. Bias affects what gets written on the request forms, which in turn influences our diagnoses. And let’s not pretend we aren’t influenced by patient names and scan appearances too. If we see a single earring or nipple piercing on a man, we are trained to think about HIV related diseases, because they are probably gay (are they though?) and therefore at risk (PrEP is a thing now!). In fact, around 20% of radiologists admit being influenced by patient demographic factors.
But it is true that, in general, we read the scan as it comes. The scan can’t tell us what colour a person’s skin is.
Can it?
Part II – AI can detect racial identity in x-rays and CT scans
I’ve already included some results up in the summary section, and there are more in the paper, but I’ll very briefly touch on my interpretation of them here.
Firstly, the performance of these models ranges from high to absurd. An AUC of 0.99 for recognising the self-reported race of a patient, which has no recognised medical imaging correlate? This is flat out nonsense.
Every radiologist I have told about these results is absolutely flabbergasted, because despite all of our expertise, none of us would have believed in a million years that x-rays and CT scans contain such strong information about racial identity. Honestly we are talking jaws dropped – we see these scans everyday and we have never noticed.

The second important aspect though is that, with such a strong correlation, it appears that AI models learn the features correlated with racial identity by default. For example, in our experiments we showed that the distribution of diseases in the population for several datasets was essentially non-predictive of racial identity (AUC = 0.5 to 0.6), but we also found that if you train a model to detect those diseases, the model learns to identify patient race almost as well as the models directly optimised for that purpose (AUC = 0.86). Whaaat?

Despite racial identity not being useful for the task (since the disease distribution does not differentiate racial groups), the model learns it anyway? My only hypothesis is that a) CNNs are primed to learn these features due to their inductive biases, and b) perhaps the known differences in TPR/FPR rates in AI models trained on these datasets (Black patients tend to get under-diagnosed, white patients over-diagnosed) are responsible, where cases that are otherwise identical have racially biased differences in labelling?
But no matter how it works, the take-home message is that it appears that models will tend to learn to recognise race, even when it seems irrelevant to the task. So the dozens upon dozens of FDA approved x-ray and CT scan AI models on the market now … probably do this^^? Yikes!
There is one more interpretation of these results that is worth mentioning, for the “but this is expected model behaviour” folks. Even from a purely technical perspective, ignoring the racial bias aspect, the fact models learn features of racial identity is bad. There is no causal pathway linking racial identity and the appearance of, for example, pneumonia on a chest x-ray. By definition these features are spurious. They are shortcuts. Unintended cues. The model is underspecified for the problem it is intended to solve.

However we want to frame this, the model has learned something that is wrong, and this means the model can behave in undesirable and unexpected ways.
I won’t be surprised if this becomes a canonical example of the biggest weakness of deep learning – the ability of deep learning to pick up unintended cues from the data. I’m certainly going to include it in all my talks.
Part III – Humans can’t identify racial identity in medical images
As much as many technologists seem to think otherwise, humans play a critical role in AI, particularly in high risk decision making: we are the last line of defence against silly algorithmic decisions. Humans, as the parties who are responsible for applying the decisions of AI systems to patients, have to determine if an error has been made, and whether the errors reflect unsafe AI behaviour.
Radiologists have a lot of practice at determining when imaging tests are acceptable or not. For example, image quality is known to impact diagnostic accuracy. If the images look bad enough that you might miss something (we call these images “non-diagnostic”) then the radiologist is responsible for recognising that and refusing to use them.

But what happens when the radiologist literally has no way to tell if the study is usable or not?
I’ve spoken about this risk before when I discussed medical imaging super-resolution models. If the AI changes the output in a way that is hidden from the radiologist, because a bad image looks like it is a good image, then the whole “radiologist as safety net” system breaks down.

The problem is much worse for racial bias. At least in MRI super-resolution, the radiologist is expected to review the original low quality image to ensure it is diagnostic quality (which seems like a contradiction to me, but whatever). In AI with racial bias though, humans literally cannot recognise racial identity from images^^^. Unless they are provided with access to additional data (which they don’t currently have easy access to in imaging workflows) they will be completely unable to appreciate the bias no matter how skilled they are and no matter how much effort they apply to the task.
This is a big deal. Medicine operates on what tends to be called the “swiss cheese” model of risk management, where each layer of mitigation has some flaws, but combined they detect most problems.
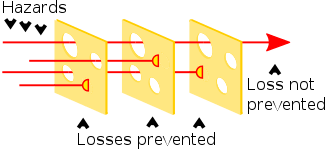
The radiologist slice of cheese is absolutely critical in imaging AI safety, and in this setting it might be completely ineffective.
It is definitely true that we are moving towards race-aware risk management practices, and the recently published algorithmic bias playbook describes how governance bodies might implement such practices at a policy level, but it is also true that these practices are not currently widespread, despite the dozens of AI systems available on the open market.
Part IV – We don’t know how to stop it
This is probably the biggest problem here. We ran an extensive series of experiments to try and work out what was going on.
First, we tried obvious demographic confounders (for example, Black patients tend to have higher rates of obesity than white patients, so we checked whether the models were simply using body mass/shape as a proxy for racial identity). None of them appeared to be responsible, with very low predictive performance when tested alone.
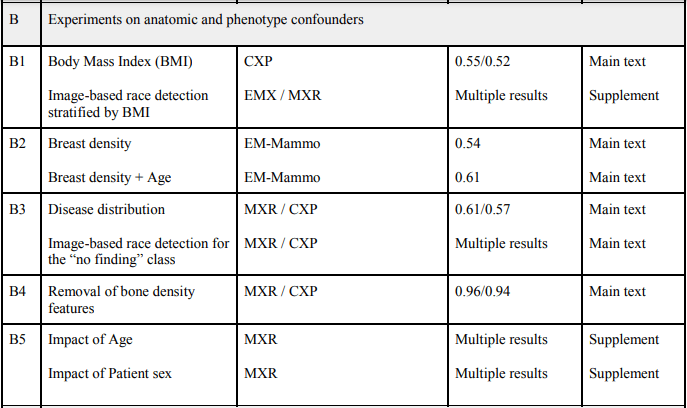
Next we tried to pin down what sort of features were being used. There was no clear anatomical localisation, no specific region of the images that contributed to the predictions. Even more interesting, no part of the image spectrum was primarily responsible either. We could get rid of all the high-frequency information, and the AI could still recognise race in fairly blurry (non-diagnostic) images. Similarly, and I think this might be the most amazing figure I have ever seen, we could get rid of the low-frequency information to the point that a human can’t even tell the image is still an x-ray, and the model can still predict racial identity just as well as with the original image!

Actually, I’m going to zoom in on that image just because it is so ridiculous!

This difficulty in isolating the features associated with racial identity is really important, because one suggestion people tend to have when they get shown evidence of racial bias is that we should make the algorithms “colorblind” – to remove the features that encode the protected attribute and thereby make it so the AI cannot “see” race but should still perform well on the clinical tasks we care about.
Here, it seems like there is no easy way to remove racial information from images. It is everywhere and it is in everything.
An urgent problem
AI seems to easily learn racial identity information from medical images, even when the task seems unrelated. We can’t isolate how it does this, and we humans can’t recognise when AI is doing it unless we collect demographic information (which is rarely readily available to clinical radiologists). That is bad.
There are around 30 AI systems using CXR and CT Chest imaging on the market currently, FDA cleared, many of which were trained on the exact same datasets we utilised in this research. That is worse.
So how do we find out if this is a problem in clinical AI tools? The FDA recommends…
…you report all results by relevant clinical and demographic subgroups…
Statistical Guidance on Reporting Results from Studies Evaluating Diagnostic Tests, FDA 2007
which sounds nice, but thus far we have seen almost no evidence that this is being done^^. In fact, even when asked for more information by Tariq et al, no commercial groups provided even a demographic breakdown of their test sets by racial identity, let alone performance results in these populations. I said at the start that I hope this research changes medical AI practice, so here is how: we absolutely have to do more race-stratified testing of AI systems°, and we probably shouldn’t allow AI systems to be used outside of populations they have been tested in.
So is the FDA actually requiring this, or has this been overlooked in the rush to bring AI to market?
I don’t know about you, but I’m worried. AI might be superhuman, but not every superpower is a force for good.


Hi Luke,
I was really interested to read this letter – especially that findings were maintained even with extreme image degradation or down to 4×4 pixels.
Thinking about why this might be I was wondering if any thought had been given to whether darker skins might absorb x-rays differently to lighter skin? I had a quick search but could not find any information on this. My thinking would be that if this was the case this would skew the ratios of lucencies of different parts of the image. For example let’s say light skin absorbs no radiation, dark skin absorbs 20 units and bone 400. In people with dark skin the ratio of areas of air to bone would be 20:400. As opposed to 0:400 in light skin. This ratio also might be maintained even when most other information was taken out e.g. this low and high frequency passes.
Not sure how plausible this is but only a thought!
Best Wishes
Raphael
LikeLike
1) The surprise is at the precision of the AI’s race-guessing ability, not at the existence of bias.
2) Please read the paper before you comment. The authors did check for that. Firstly, by blurrying and noise-scattering and resizing images to uniformly low quality, secondly, in the Discussion section they mention datasets of patients that in the same location and with the same process regardless of race.
3) Please have some grasp of magnitudes. Due to the American white population being several times larger than the American black population, the subset of American whites living in poverty is about as large as the entire American black population. A crude proxy for race such as income, wealth, or socioeconomic status would not be able to get the repeated >0.9 accuracy described here.
LikeLike
Thanks for the thoughts Raphael.
It might be a bit generous to say performance was “maintained” at 4*4 pixels, it is severely degraded, just not to random chance levels.
It is plausible there is an underlying biological mechanism, but we will need to do a lot more work to understand what is going on.
LikeLike
Very Interesting. I cannot believe this is real. While the AI learning race from a normal looking chest x-ray might not surprise me and may even seem borderline expected. The HPF 50 image really challenges everything i know about deep learning.
But deep learning algorithms also recognize x-ray devices and manufacturers with a similarly absurd auc, even when the images are distorted to a similarly absurd degree. Probably because of the characteristic noise they add to the processed images that is very hard to remove
So my guess is maybe the dataset has very few black/POC x-rays with all of them coming from a single / very few models of x-ray devices. With many of these groups being economically disadvantaged, maybe they don’t have access to expensive healthcare? and hence, might have been imaged using low cost devices?
Can be easily verified by stratifying the results on x-ray device models
LikeLike
This has been easily verified 😅
We are using datasets with tens of thousands of Black patients, with images obtained on the same scanners as everyone else.
It is well known that deep learning systems are sensitive to high frequency image information (ie texture), the only surprise here is that the texture of those “grey square” images is actually informative. We just need to find out why.
LikeLike
Hi Luke interesting but if I understand you the ML can detect nominated race even when filtered so severely that the ML could not determine what modality was used or what the findings were; if so its nonsense and may be due to embedded information in the data set such as when or where the images were obtained etc etc. rgds Bob Dempster
LikeLiked by 2 people
Hi Bob. A human can’t tell what modality it is. We haven’t tested the AI. It just means there is information the AI can use in the parts of the image spectrum that we humans don’t appreciate.
LikeLike
I’m, like, the *opposite* of a sophisticated party here, but I don’t think that’s what this is describing. My read is that the AI has become able to reliably infer what a patient’s self-reported racial identity is, not their genetic/ethnic background. This isn’t something like
“we quite reasonably need to be concerned about sickle cell anemia because you’re Black”, it’s
“in aggregate, more Black pregnant women get reported for drug abuse than non-Black women, despite not having a commensurately high rate of drug use, and the AI has intuited this very bad thing and is applying it without being told to do so AND without anyone understanding how it came to learn how to infer this.”
Again, I’m a rank amateur in this area. Please let me know if I’ve read this wrong.
LikeLike
I agree that the Venn diagram of subjective self-reported racial identity and objective(ish) genetic/ethnic identity are so similar as to functionally be a circle, but that’s not the issue.
The intention of the AI was never to determine this identity (of either kind) in the first place. Instead of doing *only* what we want it to do, it’s doing something else. Even if it was accurately printing out the local price of 6oz of Stilton at the timestamp on the images it read, we’d have reason to be very alarmed. Not for any “oh no the AI has sentience” hand-wringing reasons, but because it demands we ask what else the algorithm is adding into the output without our knowledge and/or intent.
This study’s example of undesirable output is, at a baseline, damaging to patients for the same reason that a human giving biased treatment to patients is damaging. We don’t want to add silent modifiers motivated by racial biases to medical interventions! If you’re concerned about dangerous variations in treatment, I have to assume you agree with me on that front. Doing an ultimately helpful thing for unpredictable reasons (the dog got in the car and drove to the grocery store) that happen to have potential utility is dangerous (we don’t trust dogs to drive cars).
*That* reason–that what is essentially a medical tool/intervention is doing stuff we haven’t asked it to do–is why this is a problem that needs to be fixed by evaluating and adjusting the methods that produced it. Just because the extra information it’s pulling out might be useful (or even true!) doesn’t excuse the fact that it’s doing stuff we didn’t request or intend.
LikeLike
I actually can’t tell if you’re very upset that:
1) an AI which can deliver consistent outputs of self-reported race is very bad as compared to interpreting the AI’s output as some objective definition of a patient’s ethnicity (i.e. you’re some kind of Race Realist)
or
2) you believe that self-reported racial identity is just as or more important than actual genetic markers of ethnicity with regard to treatment concerns (i.e. you are so intensely woke that I can’t fathom your worldview)
Which means I should probably just stop responding to you, as I’m either too tired to parse your comments, you’re not differentiating your position well enough to be understood, or you’re actively trolling me.
Oh, or potentially 3) You don’t understand how an AI-driven toolset works, or that programs should only do the thing they’re designed to do and nothing else.
LikeLike
Interesting article. I wish you had explained why you believe that the algorithm detecting race was a bad thing.
You wrote at length about health disparities, but never closed the loop on what that means for the algorithms. What is a simple case where, had the algorithm not detected race, it would make the right choice but didn’t?
LikeLike
I reference this paper in the post (in part ii): https://www.researchsquare.com/article/rs-151985/v1
AI systems under-diagnosed Black patients and overdiagnosed white patients when trained on the same datasets we used. In that setting, consistent performance would be preferred (for all racial groups).
LikeLiked by 1 person
Not an expert in the field so forgive me if my questions are dumb —Is the underdiagnosis and overdiagnosis of different groups a result of AI’s emergent awareness of race? Will elimination of AI’s awareness of race result in more accurate diagnosis? In terms of the ultimate goal of diagnostic accuracy, is AI’s awareness of race actually relevant?
LikeLike
What could this come from? Were the AI systems ‘trained’ on Black as well as White patients– ie. could the discrepancies you refer to result from programming?
Or could they result from differences in patient groups?
The study you reference above finds a similar result with Medicaid patients. As a group, the Medicaid patients may be slower to seek treatment or slower to receive it once sought.
In other words, the difference may be due to these patients being slightly more advanced in their illness.
LikeLike
Yes, it is likely that the model is learning racial differences to “explain” differences in the data set that have resulted from societal biases.
All of the models were trained on a variety of large datasets, which ranged from a low prevalence of non-white racial identities, all the way to equal prevalence.
LikeLike
Do the image files contain any metadata, or did the models just get raw pixel values? Was there metadata overlaid onto the image that had to be scrubbed (see this comment: https://twitter.com/MaharriT/status/1422540527212371968).
LikeLike
Just the pixels are seen by the AI model.
LikeLike
Hi Luke, very interesting work, with thought provoking results. I haven’t yet had time to go deeply into the paper, but one thing that came to my mind is a method I used a few years ago to prevent similar biases in a deep learning model.
The method I used was based on semi-adversarial training and was never published. However, it is very similar to the method employed in “Semi-Adversarial Networks: Convolutional Autoencoders for Imparting Privacy to Face Images” [https://arxiv.org/abs/1712.00321].
The crux of the idea is to add an auxiliary network on top of the initial layers of your model, where the aux network is trained to classify for the bias you are trying to prevent. The gradients from that classification loss are not propagated back to the model layers (you do not want to strengthen the bias, of course). Instead, the gradients from the classification loss are negatively propagated to the model layers (flipping the sign of the gradient), so that the initial layers of the model are encouraged to filter out any information that the aux network could use for classifying for the bias.
For the data I was working with, this worked really well, removing the bias from the model predictions while preserving the good performance.
Perhaps you have already explored such methods, but if you haven’t I think it could be interesting to test.
LikeLike
Racism has huge potential for improved medical outcomes across the board. The majority of human doctors are not very skilled when it comes to distinguishing ethnicity down to historical tribal groupings or regions and the majority of doctors are treating people outside their most familiar racial group with absurdly bad outcomes. Perhaps AI could help to remedy this until we are able to bring the vast array of Marathi and Han Chinese doctors up to scratch on how to identify a primarily Western Hunter Gatherer from a Mediterranean Farmer. It really is a matter of life or death.
LikeLike
Hi,
could this GAN behavior observed a few years ago be somewhat related to the issue you mentioned in your article?
Steganography could be a way to obtain some valid data from an otherwise corrupted image.
Click to access 1712.02950.pdf
LikeLike
Systemic Racism, in the medical profession it becomes institutional racism, is an emergent property derived from the inadvertent racism of collections of individuals who may not know their subliminal racism is making them behave that way, but the AI is not inherently biased in that all it does is recognize patterns in data. Its up to humans to remove their bias treating any patient regardless of the AI report of his/her race ID. Since there is increasing awareness that disease of many sorts discriminates based on race and gender I would assume that the more an ethical doctor knew about the patient’s ethnic base the better could be the treatment. If AI is so accurate I wonder if it could distinguish between sub-racial categories like nationality. Could it, with enough data differentiate between patients of the same race but differing susceptibility to a given disease. If this power is used ethically it could be a boon to medicine. I’m not a medical professional but I see advantage in a tool that could find out things that humans never thought of.
LikeLike
It is usually easier to just ask people their race or nationality…
LikeLike
Hi there,
Thanks a lot for this very interesting post.
I agree with everything that has been said above about racism, but as a clinician I think we should also remember that differences in diagnostic/therapies based on “racial identity” is not always racism.
I’m well aware of the fact that I’m massively biased when treating people of another culture/origin, and that those biases persist even though I’m actively working against them.
However, I found myself asking patients with fever about recent travel in sub-saharan countries more often when they were dark skinned, and this bias made me catch a few cases of malaria I could have missed. Same with TB which is very rare in my area and would’nt be looked for without key anamnestic elements based on travel and exposure.
When treating hypertension, It is – to my knowledge – well established that diuretics should be used as first line therapy in black patients.
This AI racial identification is likely to impact our practice in a lot of negative ways. However, I think we should also consider how we could benefit from it to tailor our management to each individual, taking into account the epidemiological differences between communities.
LikeLike
Totally agree Terry. We are not arguing for the removal of race from medical decision making, AI or otherwise. What we are saying is AI does something we can’t, and that it does so in a hidden way, so we need to a) be aware of it, and b) make it more explicit so we can choose how and when to use the information, rather than relying on an algorithm trained on biased practice to decide for us
LikeLike
An interesting parallel was Google’s work on an AI to diagnose disease based on fundoscopic images, which turned out to also classify male and female eyes with an AUC of 0.95+ (here’s an article about it: https://medium.com/health-ai/googles-ai-can-see-through-your-eyes-what-doctors-can-t-c1031c0b3df4)
In other CNN settings, you can throw a deconvolution layer on at the end, and at least get a sense of the features that the model is using. Did you try it with any of these models?
To a scientist, findings like this are marvelous and interesting. The fact that racial or sex phenotype leads to distinguishable patterns on fundoscopic exam or radiographic images is really cool.
You said “the fact models learn features of racial identity is bad. There is no causal pathway linking racial identity and the appearance of, for example, pneumonia on a chest x-ray”. I did not see any indication that the appearance of the pneumonia itself is different, is there? I would expect that the features that distinguish population ancestry would be in the normal parts of the anatomy. Was there any indication that the diagnostic performance of an AI would be worse in one racial group than in another?
LikeLike
Re: the last point, this work started because we were all trying to find out why AI performs worse for one group than another. We reference papers that show this happens (including specifically in several of these datasets), but it wasn’t part of our paper to reproduce those results.
LikeLike
Thanks for the insightful post. There are some research works that focus on removing bias/confounder in machine learning models. A popular direction is through adversarial training, which introduces a discriminator to encourage model to learn features invariant to confounding factors. An example for medical imaging can be found at:
Zhao, Q., Adeli, E. & Pohl, K.M. Training confounder-free deep learning models for medical applications. Nat Commun 11, 6010 (2020). https://doi.org/10.1038/s41467-020-19784-9
LikeLike
Rich people can have their X-rays read right away. Poorer people, often nonwhite people, have to wait longer. Sometimes too long…
The harms are nebulous but the benefits far clearer.
The primary affect of your research is to reduce access to medical treatment among vulnerable and underserved populations.
LikeLike
This may be very naive of me for asking, but I think of when I get an x-ray I think of having to take some clothing off and being put in a gown. Would it be worth it to make sure that the people in the study are basically nude, have hair in a cap, so that for some reason the AI is not detecting a non medical trend that could be fashion related? Could popular brand-a that is trendy among one group be what is detected? Do the Dicom images have all location data and other meta data removed from them? I work in IT security, and have had to deal with “hidden” meta data issues when publishing pictures to keep certain things private.
Did it figure out that Hospital X in Pierre, SD used one model of equipment, where Atlanta, GA used another type of system?
I read the paper, and it could be that it was too advanced for me, and I didn’t see if that was accounted for.
LikeLike
If racial recognition/detection does not lead to differential treatment by the human healthcare provider, why does it matter?
LikeLike
This research was literally an investigation of how differential treatment occurs – we cite several papers which already demonstrate that the harm happens. We were only interested in the how.
LikeLike
I am wondering if it has something to do with bone shape, structure or density of people from different races?
LikeLike
Very interesting. I would argue that the frequency-based filtering does not remove all the edge information (since edges have components at all frequencies), so the networks could be picking up different bone shapes for instance. A way to test this would be to either warp the images with some elastic transforms to distort the large-scale shape, or to apply nonlinear filters like median or morphology operators to make sure small-scale contents are removed.
Also, you could try backpropagating fullt into the image (like the deepdream method) to better see what the archetypal features look like. Could be interesting on the lower- resolution images.
Finally it seems that like all deep learning problems the issue is in the data. Clinical datasets can have biais in how the patients are selected as you pointed out. Can you reproduce these results in screening datasets? Ideally in cases were 100% of the population actually undergoes screening.
LikeLike
Luke, Thanks for your clear and detailed explanation. I imagine this has been already covered. My main question is if there is a different algorithm for each “test” or if there is a single algorithm that works across tests. What I am wondering about is that self defined “race” is not consistent across geographies and so I’ll be even more impressed if one algorithm works universally.
Also, is there any update on review and publication of the MS? (Incidentally, I was interviewed about the paper by a reporter at the Boston Globe but his editors have apparently put a stop on publishing any more about the paper.)
Thanks!
Alan Goodman
LikeLike
The obvious question is why is the author so upset by any of this. The answer is rather clear
“My religious cult dogma just went down the drain and I don’t like it”
What religious cult cult dogma? “Race has no biological basis”.
LikeLike
“AI seems to easily learn racial identity information from medical images, even when the task seems unrelated. We can’t isolate how it does this, and we humans can’t recognise when AI is doing it unless we collect demographic information (which is rarely readily available to clinical radiologists).”
This is supposedly an “Urgent Problem”.
AI recognizes reality. Reality is bad. We can not end racism until we end reality. Smash racism now! Smash reality now!
LikeLike
I don’t find it surprising at all that it is able to do this, and I think that it’s fantastic that it is able to. As a previous comment eluded to, this paves the way for more personalised medical care by offering potentially much more granularity than using a broad category completed by a patient.
It’s great the any under/over diagnosing of patients was noticed and this certainly stresses the importance of error monitoring with regards to not only variables included in the model, but lurking variables also. This information should provide insight into improving the model further, with or without the knowledge of how it actually was able to do it (though that would be useful).
LikeLike