

Alright. So, deep breath. An AI company has been cleared to sell an autonomous AI system that reads chest x-rays and, for at least some studies, sends out reports without human oversight*.
Now, there is little published evidence available online about this system, but the CE Marking process, particularly for Class IIb devices, is fairly rigorous. Hugh Harvey, the managing director of Hardian Health (a healthcare AI consulting firm with a strong focus in regulation) has blogged on the announcement itself and summarises what we know very nicely:

I agree that sounds sensible, and I can’t comment on this system directly without published evidence. I did actually chat to Oxipit when writing this and they seemed reasonable. They certainly tested their system on a huge dataset and fulfilled the requirements the regulator set for them. The product plan they shared with me is even pretty interesting and I look forward to what they do next.
But really, this article is not about Oxipit. What it is about is the idea behind the system, and what that idea means for AI safety. What the heck is a ‘no abnormality” detector?
Is the absence of a thing … detectable? Is it possible to know nothing?

In that narrow corridor
To understand my following arguments, first we need to discuss a fairly ill-defined concept in machine learning: narrowness.
Modern AI systems are often described as “narrow”, meaning they are usually very good at performing a single, often binary, classification task. For example, deciding if a bone is fractured or not. This is fairly simple task, there is a limited set of features that we need to look for, and a fairly consistent type of input image. But even then, we can see that this task is made up of a variety of subtasks and features.
For example, fractures can have different shapes.
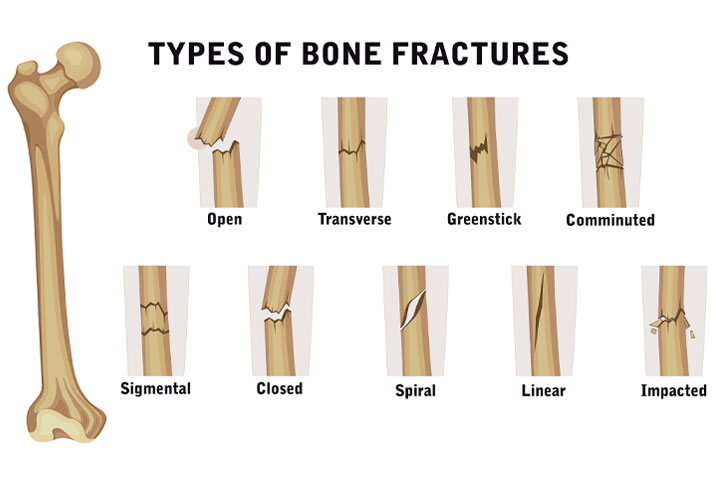
Fractures can have different radiographic features.

They can occur in different body parts.
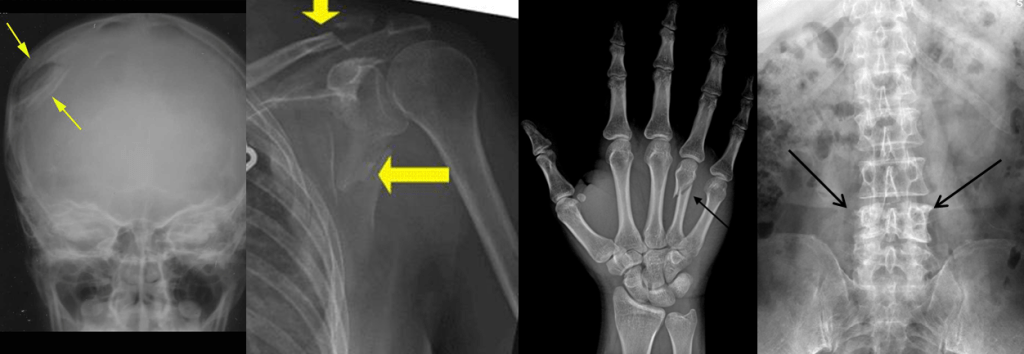
So with all of this variation … is it really a single, narrow task? Can a model even learn to detect fractures, or does it really learn to detect a variety of patterns, involving different combinations of visual features in different sets of images?
We can see that narrowness is not a clearly defined thing, where some models are narrow and some are general. Rather, narrowness is a spectrum. A fracture detector which only looks for displaced skull fractures is far more narrow than a system that is intended to detect any fracture, particularly fractures with visually distinct features such as undisplaced radial head fractures (see the “joint effusion” picture above, the only evidence of the fractured bone isn’t even in the bones, it is a change in the soft tissues).
Similarly, a broader or more general AI than a fracture detector might purport to look for multiple different pathologies in multiple different body regions.
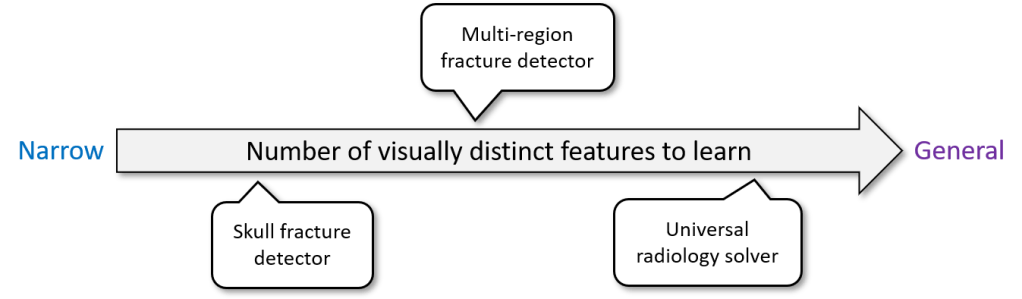
The implication is obvious. The more narrow an AI, the less it needs to learn and therefore the less training data it needs. Hence, all the reasonable claims that narrow AI works better.
In real life, some medical AI systems are very narrow. For example Viz.ai has a very successful product which looks for “large vessel occlusions” – blood clots in the brain that are very consistent in appearance and location – the very definition of a narrow task. Other medical AI systems are more broad, for example annalise.ai** has a chest x-ray interpretation system that looks for 120+ findings on a chest x-ray, many of which are highly variable in appearance and location.
But occasionally, someone builds a model and claims it can do everything.
Normal is not a distribution
Imagine you are building the visual system for a self-driving car, and you have been given a dataset of street images that have been labelled in a binary manner: safe vs unsafe. This data has been gathered by a fleet of cars, perhaps simply by noting when the driver decelerated or swerved, associated with images of whatever driving environments they happened across. The exact sort of dataset every big self-driving car team would have.

You are asked, with this data, to build a safe environment detector – if the model returns a “safe” label, the car can keep moving towards the destination. Your bosses love the idea, since they have heard that narrow AI works better, and there is nothing more narrow than a binary classification task. And of course, they love it because it means they can solve the problem without all that fancy, expensive labelling you might need if you wanted to identify a host of specific unsafe conditions.
You have a few questions, of course. What is in the dataset? Does it cover all potential unsafe situations? Are there enough examples of roadwork, night-driving, and inclement weather? Rogue wildlife? Unexpected debris?
No need to worry about all that, your bosses explain to you patronisingly. You aren’t building an unsafe environment recognition system. That would be time consuming and expensive. You only need the model to recognise safe environments. You have millions of examples of safe conditions, it’s a slam dunk.

This, quite obviously, doesn’t work. Self-driving car companies haven’t solved the problem of “safe conditions detection”. It is magic pudding thinking; the idea that you can sprinkle a few cheap ingredients in a pot and get a never-ending pot of delicious pudding that tastes like whatever you want and will make everybody happy. A free lunch, for those of us not from down-under or who are less culturally connected to fruit-and-lard-based dessert metaphors.
There is no such thing as a single narrow model to identify safe driving conditions. “Safe conditions” are not a homogeneous class, but instead are the absence of a enormous range of visually distinct phenomena. It doesn’t matter if you frame it as binary task or not, it is not a narrow problem.
To make matters worse, many of these phenomena have more in common visually with the majority of “safe” than they have in common with the majority of “unsafe”.
Here is an good example: tire spikes. There is practically no chance that deployed tire spikes occur in any driving dataset, and being low profile objects they tend to look more like normal road than they look like an oncoming truck or a pedestrian, common examples of unsafe things. There are probably even examples of safe stuff in the dataset that look a bit like a strip of tire spikes (for example, a joining point on a bridge or a traffic counting device). Motorised road spikes are even worse, looking almost identical in safe and unsafe modes!

This is the big problem with the idea of a normal detector. If the model is safe in this situation, then it must be able to distinguish deployed tire spikes from undeployed tire spikes and bridge connection points, plastic bags from pedestrians, blue skies from blue trucks, and a million other things. If it works, it isn’t a narrow AI system at all. It is a universal road conditions classifier.
Let’s pause that thought for a second and think about this from the position of a medical device regulator.
Regulating normality
Regulators classify devices based on their expected level of risk to patients, and following the lead of the IMDRF, most regulators tend to stratify risk based on two main components – the seriousness of the decision (ie will a patient die if the wrong decision is made?) and the autonomy of the AI (how much oversight does a human expert have over the process?).
Here is a nice example of a risk stratification tool for diagnostic AI systems from the Australian TGA.
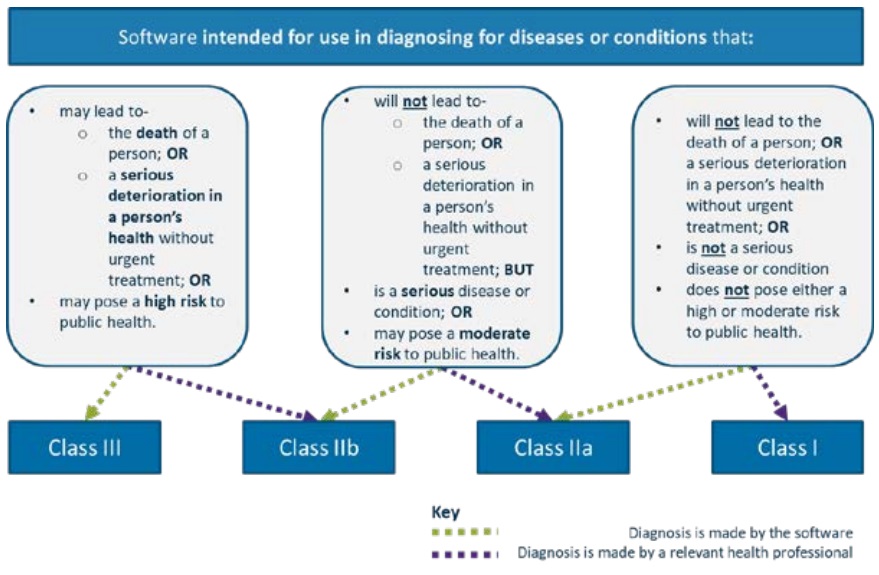
I like this particular approach because it centres the role of the health professional as the deciding factor in the risk stratification. But how would a regulator approach a “normal detector”?
The problem really comes in the first step (the top blue bar), related to the intended use, and it really highlights the sleight of hand at play in how normal detectors are sometimes framed: what sort of conditions does a normal detector diagnose?
Well, it explicitly can’t diagnose a collapsed lung, or cancer, or a raging chest infection. It has no outputs to tell you if any of these things are present, therefore if you take this risk stratification tool at face value, then by definition it is intended to be used to detect if an x-ray is normal; a condition which is not a serious disease or condition, and is in fact not even a diagnosis at all. By the flowchart, that makes it a Class IIa device (since it is autonomous).
But the AI by Oxipit was regulated as Class IIb in Europe, equivalent to an autonomous system that concerns serious disease and conditions or, if it was not fully autonomous, even potentially life-threatening ones. Why?
I’m sure you have already worked out the trap. By calling the device a normal detector, it makes us think that the model is only responsible for low risk findings. If it makes an error, it has only (incorrectly) decided a normal study might be abnormal, in which case a radiologist reads it as per standard clinical practice. But in reality, there is another sort of error it can make: what happens when it calls a scan normal and it actually contains disease? What sort of risk is there, given that this scan will never be seen by a radiologist?
Well, the opposite of “normal” is not “abnormal” in this context. It is literally anything that can go wrong on an x-ray. That includes non-serious conditions, serious conditions, and potentially fatal conditions. It includes urgent, soon-to-be-fatal conditions, where a wrong answer can lead to death, since those can happen in chest x-rays too.
From a regulatory perspective, it is hard to see how a device that makes decisions about life-threatening pathologies and can misdiagnose them with no human oversight is not categorised as Class III.
From a regulatory perspective, it is hard to see how a device that makes decisions about life-threatening pathologies and can misdiagnose them with no human oversight is not a Class III device.
This is really my point. You don’t get to say that “recognising normal cases” is not a decision about abnormal cases. You can’t make a low risk system to detect “not cancer”, because the task is inherently also about detecting cancer.

This is clearly what the EU regulators thought too, since they put the Oxipit system into class IIb and not IIa, implying they see the system to be making decisions about risky things. I admit to having serious ongoing reservations though. The MDR guidance in the EU states the following:

Somehow TUV Rheinland have decided that this AI falls into a middle ground. They aren’t treating this device like a “normal detector” that only makes decisions on low or no risk cases, they have recognised that it makes decisions that could lead to a serious deterioration in health, but for some reason they stopped short of recognising that those decisions could produce irreversible harm or lead to death. I’m not sure why, but I would love to know.
That said, I’m not here to second-guess the regulators or criticise anyone. This isn’t about Oxipit specifically or TUB Rheinland. This was just the medical context these devices live in.
To close out this piece, let’s step back and look briefly at the relevant computer science.
Investigate sensor anomaly
The basic underlying ML framework for a normal detector is generally called outlier detection (or sometimes “anomaly detection”). You don’t train a model to recognise anything in particular, just to identify when an input is unlikely enough to be an outlier. This works well in numerical data, since all you need to do is simply define a centre, direction, and distance, and anything outside of that region will be considered an outlier.
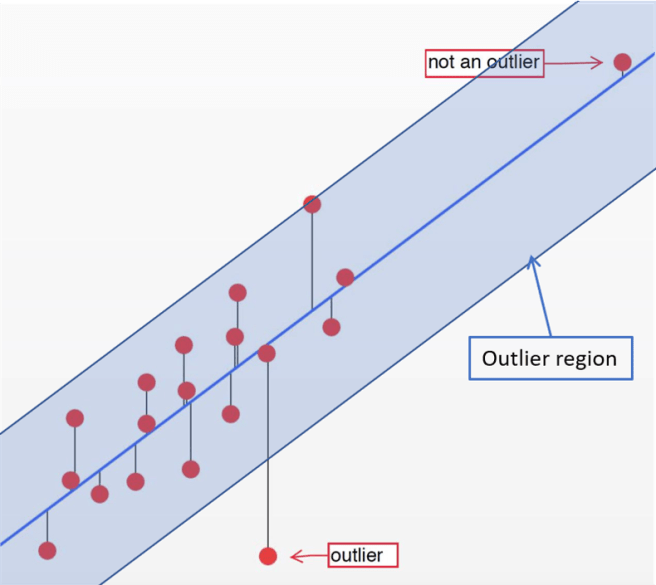
But what about in images? What makes one image an outlier compared to another? How do we define our centre, direction, and distance? For example, which picture here is an outlier?

In computer vision, visual features can be thought of as directions in the space of image data.

So in the space of “all cat photographs”, big eyes might be one direction, an open mouth could be another, red fur might be a third, and so on. The further you go in that direction, the bigger the eyes get or the wider the mouth opens. You move far enough in one or more of these directions, say, to really big eyes and red fur, and it becomes an outlier.

Here’s the problem though: this is not how outlier detection works in computer vision at all. This is pure anthropomorphism; when we humans assume that an AI model cares about things we care about and makes decisions just like we do.
You see, all of those features mentioned, like big eyes or red fur… we are assuming that the AI considers the same sort of features relevant to decision making that a human would. It doesn’t, at least not often and not in the way we do.
So what does AI do? The good news is this wasn’t actually a hypothetical question – the cat problem has a real-world answer. So which cat does a real-world, well-trained object detection AI think is the biggest outlier above? ^^

In this case, it is the most neutral looking (to a human) picture of the cat is the outlier, because the AI thinks it isn’t a cat at all. While this is an exaggerated example and relying on an adversarial attack to make my point is a bit cheeky, it demonstrates the crux of the matter: AI makes decisions in ways that rarely align perfectly with human values. In fact, this has now been formally described in Shortcut learning in deep neural networks by Geirhos et al:
Never attribute to high-level abilities that which can be adequately explained by shortcut learning
Morgan’s Canon for machine learning
where “shortcut learning” is another term for “relying on features a human wouldn’t expect to work”.
There is a ton of work on this (and I can’t do it justice here), but essentially if you look into what neurons in deep networks learn, they are almost never human-recognisable features. They are messy, inhuman, entangled things. Since these features are directions, and how much they are present in the image is a distance measure, then direction and distance aren’t really meaningful. No matter what direction you move in, and how far you move, the features that change will tend to be obscure far more than they are understandable.

So in that case what does it mean if you move too far in one direction in a deep neural network, where there are millions of possible directions? What does a combination of directions mean?
I’m gonna get flak for this, but I have to say it:
Outlier detection in deep neural networks is, mostly, magic pudding thinking.
By this I mean that unless we can force neural networks to learn disentangled, meaningful (to a human) representations of their input data, any notion of feature direction and distance are going to be meaningless for real world problems, and we need to be skeptical of systems that claim to detect outliers. Just like the cat that moved too far in the direction of guacamole without any meaningful change in appearance, a mathematical outlier in the representation space of deep neural networks is unlikely to be an outlier in the clinical space of making safe medical decisions, or in the natural image space of all possible traffic conditions.

End of the day, if you want a model that can use distance to differentiate between normal and abnormal x-rays, or safe and unsafe road conditions, if you want it to be safe you can’t simply cut corners and only show it examples of the safe majority class. I guess there is a chance it could work, but you will have no guarantees and you are likely to run into serious risks. At minimum, you need to test it for every conceivable abnormal or unsafe condition to make sure it performs safely on them, especially the ones that don’t exist in your training set and it has never seen before.
Which brings us back to healthcare. While I was writing this post, a research paper was published which does something very similar to Oxipit. This system is not yet on the market but the authors are commercial AI developers. I had something to say about it :p
I think this probably needs a second blog post, so I will address it in more detail later, but the take-home message was they “triaged” ~65% of mammograms into a “normal” category, thereby skipping any radiologist review at all. Which is not triage:

It is also not quite the same as what we have been talking about here but still feels like magic pudding thinking. Even with their strictest system, the studies that would be called normal and go unseen by a radiologist would contain ~7% of all cancers (sensitivity ~93% for cancer detection at that operating point).
So what does this all mean? Is normal detection bad? Does it never work? Am I just an AI naysayer? A machine learning demonizer?
A healthy dose of skepticism
As always, I like to think that I am an AI optimist who simply wants to make sure we aren’t killing people through a lack of caution. Normal detection, if it works, is a huge deal. That’s why people talk about it.

So how do we achieve these massive benefits without hurting people?
In my opinion, and echoing Raym, calling these systems “normal detectors” (or “triage systems”) is putting what you want it to do ahead of what it actually does.
What these systems actually do is make decisions autonomously about all of the cases they see, about all pathologies that could be in those cases… including the dangerous ones. This makes them high risk devices. We need to treat them with the respect and caution they deserve.
Practically, in my opinion, we need to we regulate these devices not based on what they are called or what cases they operate on a majority of the time, but based on the worst mistakes they can make.
If the AI system will foreseeably make autonomous decisions for life-threatening pathologies, then it is class III. No exceptions.
Summary
I thought this was pretty long so here is a final summary:
1. Autonomous AI systems are being cleared by regulators and reported in top medical AI journals.
2. The language used around these models minimises these risks – “normal detectors” and “triage systems” sound safe.
3. The idea that these systems can make those decisions safely, without dedicated training for each pathology and without dedicated testing to demonstrate they are safe for all serious conditions, is implausible at best. Magic pudding thinking at worst.
4. At least in my opinion, any model which will foreseeably make decisions on life-threatening cases must be regulated as a class III device and be subjected to the highest levels of scrutiny.

It’s an interesting topic. For once I may disagree with you on a few points (I’m generally a big fan of your writing).
So, first, the big one – it is not possible to detect normal by spotting abnormal. But it is possible to detect abnormal. Much as it is possible to falsify, but not confirm (prove) an hypothesis empirically. You can categorically state that some feature of something is out of bounds. That it is more extreme than you have seen in your data. But inversely, just because it is less extreme does *not* mean the something is normal in nature. For that you would have to examine all relationships between all features. A millipede may have hundreds of legs, dragonflies may have 4 wings… but nothing has 4 wings and hundreds of legs. Relational anomalies between and amongst features can not be considered exhaustively. The combinatorial complexity of this fast becomes intractable. I think you generally agree with this. The devil is always in the detail, right?.. It’s not just that all features are not considered. It’s that all combinations of features are not considered.
Another item I’d highlight: triage can be safe, but it gets conflated. Prioritization triage is very different to filter triage. If a triage system flagging you as normal, drops you from being seen by a human, when you otherwise would have been… this is risky. Very bad things could happen. If a triage system does not filter you (you keep on the routine checkup rota as you would otherwise, for example), but if flagged as abnormal you are prioritised for an early visit to be seen in person… this is (theoretically) safe. Risk is only reduced. In reality of course there is a practical risk that finite resources will be diverted. Possibly inefficiently. Let’s assume (optimistically) this is a non-resource-reducing scenario.
So priority triage is very different to filter triage. ‘Triage’ is not bad, per sé. The claim is not dangerous or wrong. The model of reaction to its predictions might be.
In the optimistic, non-resource-reducing, priority triage setting, anomaly detection is meaningful, doable, and useful. And not magical. The devil is in those caveats.
LikeLike
Thanks Phil. I feel like I agree with all that? I think the point I was trying to make is that “normal detection” as a task is ill posed to begin with and we need to be careful, and that conflating prioritisation triage (the way the term tends to be used) with filter/battlefield triage is a bad idea.
LikeLike
In addition to the question of which regulatory risk level is appropriate, what is your view on what the clinical validation should look like?
If one claims a product recognizes ‘normal’, and indeed this means the absence of anything considered ‘abnormal’, how does one design a clinical study for that? What about rare conditions, should you power for each possible abnormality? This seems extremely challenging to me.
LikeLike
Extremely strong claims (that you can safely differentiate any serious abnormality from “normal”) need strong evidence.
At minimum I’d expect a performance estimate for all serious conditions the model could see (i.e. define a set of life-threatening and serious conditions in that modality and test on them specifically with adequate power). The risk is carried in these cases. Ideally we’d be aware of what constitutes a different image feature in these conditions too (i.e. hidden stratification) and make sure we test all visual variants of these conditions, but we still don’t even know how deep nets define visual variants.
But end of the day the easy solution is make it class iii. Class iii means real world testing/clinical trials. Risk = measurable harm in a large enough study.
LikeLike
“Imagine a situation in which you are driving a car from a reputable manufacturer with the latest artificial intelligence solutions built in. You are speeding down the highway knowing that AI tools will make sure the car doesn’t make a mistake in as many as 99.2 percent of cases. Suddenly, approaching a curve, you see that another car is flashing by in the same lane from the opposite side. Will you then grab the wheel or not – believing that the AI system will avoid the obstacle?”
– Jakub Musiałek, CEO of Pixel Technology
Classifying a fully autonomous system as anything other than a Class III risk is nonsense. I’d like to borrow one more quote, this time from a Hardian Health article: “Regulations say nothing about legal liability after all.”
I see the move to fully autonomous triage as a step in the wrong direction. In the shadow of grandiose pronouncements, the manufacturers of AI CAD systems have had to spend the last few years convincing radiologists that they care about improving and simplifying the medical workflow, not replacing it entirely. But I feel like Oxipit decided to open Pandora’s box.
LikeLike
It would be fair to mention that you are a CEO of a start-up that develops CADe/x software, no? “Step in the wrong direction”, give me a break. You know very well that this is a financial threat to you, not a threat to patients. I’m really happy that Oxipit (and other developers of autonomous systems) is finally moving the field towards cost-effective tools that *actually* improve the workflow.
LikeLike
I’ll get right past the unreasonable personal attack and jump to the point…
I have the utmost respect for Oxipit. They and Arterys are definitely one of my big role models and I think of them as someone who is paving the way for CADe/CADx into real clinical practice in Europe. But equally, I think a fully autonomous system is a road to hell: similar to the comments made by machine learning experts who said radiologists were not needed at all.
LikeLike
Dear Lauren,
thank you for the thoughtful article and the thoroughly motivated criticism!
I think the 7% (ie 93% sensitivity) number that you cite is not accurate for the fully autonomous operation, but applies to the combined system, taking into account that readers have limited sensitivity. The AI-autonomously „triaged“ cases are predicted with a sensitivity closer to 98%.
(I am working in said company and have been a reader of your blog for a while with great interest!)
Best,
Zacharias
LikeLike