

Today we continue looking at breakthrough medical deep learning research, and review a major paper from Stanford researchers that reports “dermatologist level classification of skin cancer”, published in Janurary 2017.
As a reminder, a major focus of this dive into the state of the art research will be barriers to medical AI, particularly technical barriers.
This week I thank Andre Esteva, one of the authors of the paper, for answering several questions I had.
Like last week this article is about 3000 words, so I will include another summary box at the end for the TL:DR crowd 
Standard disclaimer: these posts are aimed at a broad audience including layfolk, machine learning experts, doctors and others. Experts will likely feel that my treatment of their discipline is fairly superficial, but will hopefully find a lot of interesting a new ideas outside of their domains. That said, if there are any errors please let me know so I can make corrections.
The state of the art
First up, I want to remind everyone – deep learning has really only been around as an applied method since 2012. So we haven’t even had five years to use this stuff in medicine, and us medical folks typically lag behind a bit. With that perspective some of these results are even more incredible, but we should acknowledge that this is just the beginning.
I’m going to review each paper I think is evidence of breakthrough medical automation, or that adds something useful to the conversation. I’ll describe the research, but spend time discussing a few key elements:
The task – is it a clinical task? How much of medical practice could be disrupted if it is automated? Why was this specific task chosen?
The data – how was the data collected and processed? How does it fit in to medical trials and regulatory requirements? What can we learn about the data needs of medical AI more broadly.
The results – do they equal or beat doctors? What exactly did they test? What more can we glean?
The conclusion – how big a deal is this? What does it show that we can extrapolate more broadly?
Stanford’s Nature paper on skin cancer and other skin lesions (February 2017)
The task:
Dermatology is the medical specialty that mostly focuses on skin lesions. They deal with skin cancer (10,000 deaths per year in USA) and other neoplasms, rashes and skin manifestations of systemic diseases.

Skin lesions are really varied but really hard to tell apart, even for humans
The authors trained a deep learning system to perform several tasks related to dermatological practice. The headline result is the assessment of “needs biopsy” lesions, which is identifying patients which might have skin cancer and need further workup. They also assessed the ability to identify cancer directly from the images, and a more complicated task trying to diagnose lesion subgroups.
Data:
They trained the system with 130,000 skin lesion photos, from 18 different public databases as well as private data from Stanford Hospital. Unfortunately the paper wasn’t super clear about where the data came from and how it was structured, so I am not really sure what the ground truth training labels were. In the paper they describe the data as “dermatologist labeled”, but there is also mention of biopsy results in various locations. I think we can assume that a big chunk of this data is labeled by a single dermatologist, without biopsy results.
Interestingly, how the data was labelled is quite different from last week. Instead of grading images with a score, they looked at all 2032 dermatological diseases they had data for. Since many of these diseases have a handful of examples (and therefore can’t be learned by current ML techniques) they created an ontology of disease. This is essentially a tree-structure that divides the diagnoses up into groups based on appearance and clinical similarity.

Lesions are grouped together by visual and clinical patterns, so each category at each layer of the tree is useful for clinical tasks.
By doing this, they can identify lesion groups rather than diagnoses. In the paper they show results for identifying lesions in the top 3 classes (benign, malignant, non-neoplastic) and the next layer down, with 9 classes.
They validated/tested the system on a dataset with 1950 biopsy proven lesions. In the headline “biopsy or not” experiment they compared results against between 21 and 25 dermatologists. In the other experiments they used 2 dermatologists.
The prevalence of disease in the training set is not described in the paper, but reading between the lines the data must be heavily enriched for positive examples of cancer. For example, in Figure 1 it shows that 92% of melanocytic lesions were malignant, presumably describing the training data.
In the test set the prevalence was reported. There were three types of lesion: epidermal, melanocytic and melanocytic with dermoscopy (which a better camera, essentially). Malignancy made up half of epidermal lesions, a third of melanocytic lesions, and almost two thirds of melanocytic/dermoscopy lesions.
The prevalence of these lesions in clinical populations is apparently not clear in the readings I looked at, but it must be below 5%, and is probably below 1%. So the validation sets are heavily enriched.
Regarding the data quality, the skin lesion photographs are typically around 1 megapixel each in resolution. These images were shrunk to 299 pixels square, which is 0.08 megapixels (about 90% less pixels). This is a baked-in property of the network architecture they applied, other image sizes cannot be used.
They also excluded blurry and far-away images from testing, but these pictures were still used in training. They do note that many lesions had multiple pictures (i.e. from different angles) but they went to a good deal of effort to make sure that no lesions were present in both the training and test sets.
Network:
They used a pre-trained version of the Google Inception-v3 deep neural network, which is one of the best performing image analysis systems used today. Pre-training typically means they took a network already trained to detect non-medical objects (like photographs of cats and cars), and then trained it further on the specific medical images. This is why the network would only accept 229 x 299 pixel images.
Results:
This paper was what I consider the second major breakthrough in medical deep learning. They achieved better performance than most of the individual dermatologists, as well as the “average” dermatologist, from their panel that they presented for comparison.

This is essentially a ROC curve, just flipped over. The dots are dermatologists, and the blue line is the algorithm, which is further to the top right (meaning better performance).
Similar to last week, you can imagine drawing a line of best fit through the dermatologists. Unlike last week, this line would actually be worse than the algorithm! Breaking that down, this system was better at identifying lesions that ended up being malignant after a biopsy. It could pick up more positive cases while getting fewer false positives compare to most of the individual doctors*. This is a big deal.
The other experiments are less earth-shaking, but are very interesting. They showed how accurate they are at identifying the top level and second level of their tree ontology.
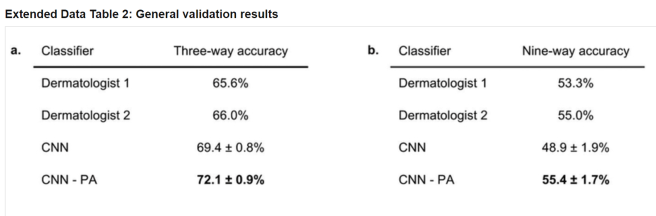
I’ll explain CNN vs CNN-PA in a little bit, it is super interesting.
This shows that at the top level of the tree, performance is better than dermatologists, but at the second order branches performance is only about the same.
Discussion:
This research has some very interesting implications for visual AI systems in medicine.
The task: the headline result is deciding whether a lesion needs a biopsy or not. This is the exact clinical task that dermatologists perform when looking at possibly malignant skin lesions, so it is a great choice.
Essentially, when a doctor makes a choice like this, they want to biopsy all the cases of cancer they can and not biopsy the benign cases. This is because every biopsy performed increases the cost, pain and risk involved.
Since the ROC curve trades off those exact quantities, number of cancers missed vs number of false positives, it is a great way to look at the comparison. And the system outperformed dermatologists. Quite literally, at almost every operating point, the deep learning system had more true positives and fewer false positives. For the first time ever, a deep learning system convincingly beat doctors at a task they are specifically trained to perform.
The data: the major point of interest here is the tree-structure they used to organise their data. This captures the complexity of medical practice (>2000 diagnoses) but also gives us a sensible way to simplify the task. They could choose any level of the tree to train their algorithm and make predictions, a trade off between granularity and data availability.
The reason we can’t train medical AI systems to learn all the diagnoses is because of the rarity of most medical disease. Across medicine, and in dermatology, most conditions are rare. Many occur at less than one in a thousand, and rates of one in a million are not uncommon. I have said previously a good rule of thumb is that a deep learning system needs about 1000 training examples per class to learn effectively, so to have enough examples for the rare diseases you would need hundreds of millions of cases.
The real success of their approach is that they optimised the granularity of their labelling based on the amount of data available. They didn’t just say “let’s use the 3rd level of the tree”, they said “along any branch, let’s use the deepest node that contains 1000 examples“. In some cases, this might be the 3rd layer, but in other cases it might be much further down the tree (as the diagnoses in question are more common and have more examples).
By doing this, they created a label structure with 757 classes. So they can’t do “diagnosis” in the sense that they can’t identify all 2032 diseases in their data (although neither can dermatologists), but their training is a fine-grained as is practical.
And the take home message is that it works. Let’s review that table from the results.
The “CNN” results are when they trained the model on the specific task they were trying to perform – either three way or nine way classification. The “CNN-PA” results are for when the system is trained on their partitioning algorithm – the 757 classes that contain 1000 examples each.
This is sort of a surprise. Training on one task and applying it to a new one is called “transfer learning”, and is generally inferior if you have enough data to train on your task specifically. But because they structured their labels in an ontology where the branches are related to the appearances, they see a benefit in the upper level task with lower level labels.
One way to think about this is that learning is a statistical process. The features a deep learning system learns to recognise a class are simply the features that are most useful for the task. So when you have a broad class (like ‘malignant’) which is made up of multiple different diseases with different numbers of examples, the system will favour learning the most commonly useful features. The less commonly useful features, like those that distinguish between two rare but similar diseases, might not be learned. So when you have get to the edge cases between the super-classes “benign” and “malignant”, a system trained only to recognise those classes might never have learned the features that separate a seborrhoeic keratosis from a squamous cell carcinoma.

This t-SNE visualisation from the paper shows that while the major classes of lesion do cluster together, there are edge cases with overlap. Training on more granular classes should/did help correctly identify these confusing images.
This brings us to a major topic in medical AI – data engineering. We already touched on this last week, but I want to spend some time on it today.
AI has a history of needing humans to codify their knowledge for computers. Initially with expert systems like MYCIN, this meant writing rules that roughly encapsulated human knowledge. These systems were unwieldy and prone to failure when challenged with unforeseen problems. After expert systems, machine learning could take features of data and discover relationships. The problem now was that you had to pick the right features. In image analysis, this meant hand-crafting image features – capturing human knowledge in a mathematical way. An example would be telling a computer system to find the relationship between bone density (measured by the number of bright pixels on an xray) and fractures. This approach was less brittle and less time-consuming to program, but we still had to be able to convert our knowledge into numeric features.
Deep learning goes a step further, it takes in raw images and finds patterns for a task. No human knowledge input, right?
Well, no. Humans still decide on the data that goes in, and the labels that define the task. Pick the wrong data and the wrong labels, and the system won’t work. Last week, the Google team paid many ophthalmologists to score their cases, to increase the accuracy of the labels. Both Google and the Stanford team decided to downsample their images. These decisions were based on expert knowledge, that individual ophthalmologists’ labels are inaccurate and that shrunken images still contain useful diagnostic information.
This week the research team was even more explicit in incorporating knowledge into their data, and they spent a very significant amount of effort to build their ontology. This required experts to identify common disease subgroups, using their knowledge to organise their labels in a way that helped in any task they might want to perform, with any amount of data.
So one way to understand the history of AI is as the transition from knowledge-engineering, to feature-engineering, to data-engineering. We do less work than ever before to codify human knowledge, but it isn’t no work.
This also could tell us something about the future of AI. Each transition has resulted in systems that are less brittle and more able to deal with complex data in more “human” ways. Defeating the need for data-engineering might well be the key to the next stage of AI. If we can, then you could simply supply any data to an AI system, and it will do the best job possible to solve a task. That sounds a lot like general artificial intelligence.
The results: relevant to the idea of narrow vs general intelligence, this research tells us that data is a major limiting factor to the breadth of learning. If we look at the results provided, the system is superhuman at “biopsy or not”, and “benign, malignant, non-neoplastic”, but only human** at the 9-class task.
I think it is safe to assume that this is an issue about data size. As we move down the tree, each node has fewer examples. I suspect that at the next level down, a 22-class problem according to their diagram, the system would be sub-human in performance.
It would be great to know the exact number of cases at each point in the tree to be able to estimate this effect more accurately, but unfortunately that information is not available. Interestingly, and counter to my usual rule of thumb, there should be more than 1000 cases in each of the 2nd and 3rd level nodes, and it doesn’t seem like this is enough for superhuman performance. Maybe we need to expect even harsher data requirements if we truly want to outperform doctors.
The impact: skin lesions are super common, and skin cancers are the most common malignancies in people without much melanin in their skin. Skin cancer is a leading causes of death among middle aged adults, particularly in Australia (where beaches plus the damaged ozone layer increase our risk).
Nowhere near enough people go for mole checkups, and that shows in the death rates. So imagine if you could just take a photo on your phone and get an opinion better than a dermatologist on whether it needs a biopsy.
Well, imagine no longer.
In this recent video from Wired, the group who did this research look well on the way to turning their system into an app for your phone.
It will be very interesting to see how this is regulated. There is a compelling case that this technology could save a huge number of lives (there are more than 10,000 melanoma deaths per year in the United States alone), but it is still currently unclear how thoroughly something like this will need to be tested before it can be put into practice.
When this does hit the market, say in the next year or two, what happens to dermatologists? Looking at lesions is a very significant part of their work. Are they going to see their jobs evaporate?
I doubt it, at least for a while. Dermatologists also do the biopsies, and without a doubt the demand for skin biopsies is going to skyrocket. We may actually see a shortage of dermatologists in the near term.
Longer term though, I suspect we will see task substitution; non-doctors will be trained to do biopsies. Taking the doctor out of the loop here will be a big deal from a regulatory standpoint, but the massive cost savings (particularly as demand increases) will make it inevitable.
What of dermatologists then? Well, this system can only identify 9 subgroups as well as dermatologists, out of 2032 diagnoses. For now, dermatologists have the edge in something like 2023 diagnostic tasks.
But that won’t last, as more data lets the system traverse the tree with more accuracy. The number will shrink over time. How fast that process occurs will define the point where we reach dermatology escape velocity.
So those are my thoughts about the second big breakthrough paper in medical AI, from January 2017. You probably realise that these two major breakthrough happened within two months of each other. For a second there it looked like we would all be out of jobs within the year 🙂
Unfortunately, or thankfully depending on your perspective, we haven’t seen anything quite on this level since. Next week we will look at some other recent papers that don’t quite make the cut, but can still help us understand the limitations of deep learning in medicine.
See you then
SUMMARY/TL:DR
- Stanford (and collaborators) trained a system to identify skin lesions that need a biopsy. Skin cancer is the most common malignancy in light-skinned populations.
- This is a useful clinical task, and is a large part of current dermatological practice.
- They used 130,000 skin lesion photographs for training, and enriched their training and test sets with more positive cases than would be typical clinically.
- The images were downsampled heavily, discarding around 90% of the pixels.
- They used a “tree ontology” to organise the training data, allowing them to improve their accuracy by training to recognise 757 classes of disease. This even improved their results on higher level tasks, like “does this lesion need a biopsy?”
- They were better than individual dermatologists at identifying lesions that needed biopsy, with more true positives and less false positives.
- While there are possible regulatory issues, the team appears to have a working smartphone application already. I would expect something like this to be available to consumers in the next year or two.
- The impact on dermatology is unclear. We could actually see shortages of dermatologists as demand for biopsy services increases, at least in the short term.
*There is a good argument that these results are slightly unfair to the dermatologists as a collective group – the “average” dermatologist they present at the green cross is definitely pessimistically biased (for math-y reasons). However, it is fair to say that the system does appear to be better than almost all of the dermatologists they tested, which is really what we care about (because you don’t have a panel of doctors looking at your skin lesions in clinical practice).
**Isn’t it strange to feel disappointed that an AI system is only as good as a human doctor. This is the world we are heading towards.
Posts in this series
Stanford and dermatology
Next: Other deep learning papers of interest

Luke, thanks for your insightful and accessible review of our work. It’s great to see people who can navigate the two worlds of medicine and CS/AI. And nice work on your recent paper!
LikeLike
Thanks very much Rob. I loved your paper, so hopefully I did it justice 🙂
LikeLike
@rob Is the Stanford code on github? Also, the paper says the data is publicly available – could you provide details on how to access it for free. Thanks.
LikeLike
Hi Henry,
The code is not on Gith. Most of the data are publicly available– we compiled a lot through google image searches, but also used Stanford hospital archives of non-identifiable lesion images. For the test sets, free biopsy-proven images are available through the ISDIS ISBI challenge. http://isdis.net/isic-project/.
Rob
LikeLike
This is very interesting, thanks for another great read. I really hope that this does spread across more than the USA and allow every doctor on earth to be able to diagnose more effectively.
Have you got any tips for someone interested in this kind of research who wants to contribute?
LikeLike
Thanks!
The question about contribution probably depends on your skillset. Medical knowledge is highly valued in these research groups, particularly if the people with that knowledge also understand the technology. Even if it is just for working out how to use data, as we saw in this paper the structure of the data was a key insight.
Computer science skills are obviously important, but these technologies are pretty user friendly so you can learn how to use them relatively quickly. That said, the more deeply you understand them, the better!
We have actually got a lot of mileage in our work from people with biomedical statistics knowledge, which often looks at the same problems as machine learning, but in quite different ways.
So I guess, if you have some of those skills, try to find out if a group near you needs them. If not, try to develop the skills! I have a list of MOOCs (massive open online courses) on this page that I am confident can take you from beginner to proficient in deep learning (because that is how I learned).
LikeLike
Thanks for the advice. I’ve been working through “Hands-On Machine Learning with Scikit-Learn and TensorFlow” by Aurélien Géron. I did Reproducible Research on Coursera which helped me a huge amount with any research I’ve done since, would recommend it to anyone who wants to drill down in details on other peoples work. I am always amazed when people can in less than a day replicate and refute another persons work, it really is amazing what we can do using R and Python.
I will try a few more as I sit unemployed for now.
The other thing I was looking at is how do we prevent more people ending up in hospital in the first place. Traffic deaths can most definitely be reduced by AI can help with. The thing I am looking to get out into the real world is automated reporting of road-hazards using deep learning.
There are a few groups trying it out but nobody is really taking the initiative. It is the kind of thing I would expect an automated car maker to fix as a by-product of their machines but I have yet to see one claim to do it.
As a quick aside, are you a fan of 80000hours.org at all?
LikeLike
I actually referenced 80000 hours in my first blog post. I like the concept, for sure. Particularly in medicine, it is easy to assume you are making a positive impact when your marginal impact is pretty much negligible.
LikeLike
Reblogged this on The Secret Guild of Silicon Valley.
LikeLike
Thanks to write. This is realy nice information.
https://www.varnapigmentation.com/surgery-services/
LikeLike
Hi,
I would like to say that this blog really convinced me, you give me best information! Thanks, very good post. It’s really interesting… Keep sharing with us such interesting topics…
Regards,
Dermatologist in manchester
LikeLike